内置HTTP模块 Node.js 中有 HTTP 这个内置模块,HTTP 模块允许 Node.js 通过超文本…
node模块
node 中间层怎样做的请求合并转发(node作为中间件做接口转发)
1) 什么是中间层 就是前端—请求—> nodejs —-请求…
使用 Mocha 和 Assert 测试 Node.js 模块(中)
在上文最后一步中,我们手动测试了我们的应用程序。这将适用于个别用例,但随着我们的模块扩展,这种方法变得不那么可…
node相关知识点(上)(node指什么)
Node 里的模块是什么? node 中,每个文件模块都是一个对象,它定义如下: function Modul…
(转)Node.js 项目的配置文件(配置nodejs环境变量)
作者:老雷 原文地址:https://morning.work/page/2015-09/nodejs_pro…
Electron 使用Node原生模块(electron node版本对应关系)
本节我们学习如何在 Electron 中使用 Node 原生模块。 Electron 支持原生的 Node 模…
易语言调用node模块
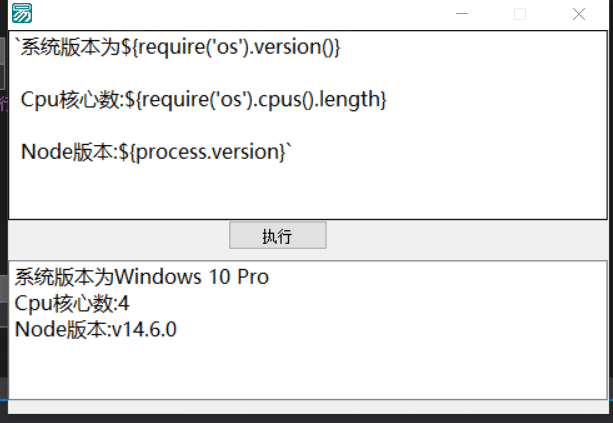
调用自定义模块需要全局安装,可以更改模块输出文件到根目录,也有点麻烦可能用的少就输出到临时目录了.